Introducing Graphene
Today, I’m excited to announce our new company, Graphene, and the open source launch of our namesake data analytics framework.
AI is finally starting to deliver on its promise to revolutionize data self-service. The raw intelligence of LLMs, coupled with modern agent harnesses and context management techniques, has reached a point where data leaders actually trust agents to do real data work. Given how rational and inherently skeptical data professionals tend to be, that’s saying a lot.
But the agents doing that work are mostly trapped inside SaaS products. One agent per tool, each with a narrow window into your context and an equally narrow toolset to take action. Your BI tool has an agent; your docs workspace has an agent; you write code with another; and you’re the integration layer between all of them.
I can’t help but feel like we’re still in the horseless carriage era. AI is the new engine, and traditional SaaS is the carriage.
What people actually want
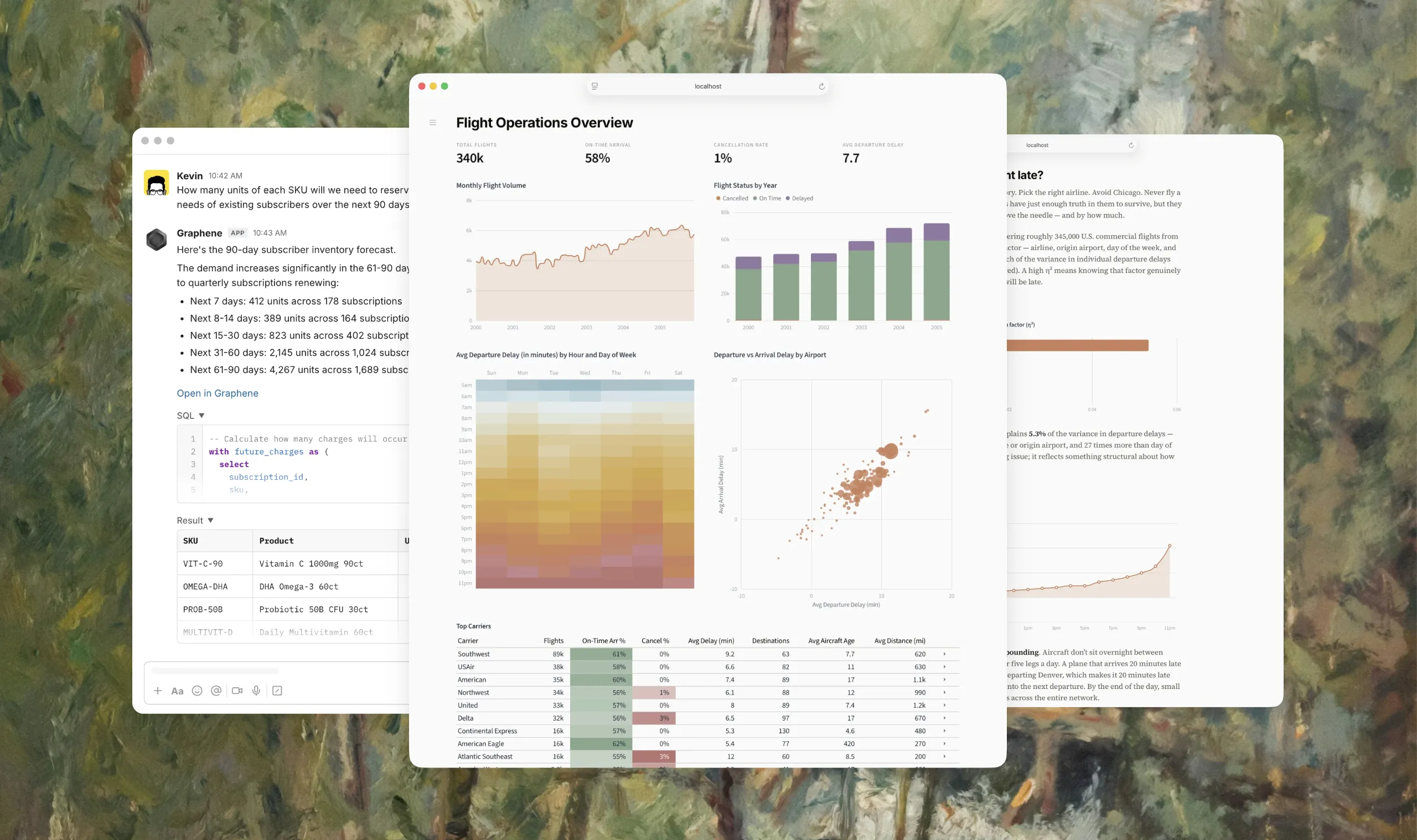
My co-founder, Grant, and I spent a long time just talking to people and listening. What stood out was a desire to use their coding agent for everything instead the myriad of micro-agents embedded in their tools. Create a dashboard, pull a customer list to feed into a marketing campaign, use usage data to create a better implementation plan for an upcoming feature.
This makes sense, because data work is rarely the end in itself. It’s a part of a broader workflow. Our tools and our agents should orient around this fact.
At the same time, the nature of data work itself is shifting. Data professionals are becoming context engineers. Rather than performing the end work themselves, they’re curating the context that allows agents to do it instead. This is real engineering work, and deserves engineering-grade tools: version control, bash, code review, diffs. Not typing into text boxes on a web page every time something about the business context changes.
Introducing Graphene
We’re building Graphene as an AI-native data platform to solve these problems. The core is being open-sourced so that your business logic and mission-critical reports are never locked in.
Graphene’s core combines a semantic layer with dashboards-as-code to give a coding agent everything it needs to do serious data work. It gives you the full power of ANSI SQL without sacrificing the governance of a traditional semantic layer. Metrics, dimensions, dashboards, and notebooks live in your repo, versioned alongside everything else.
Besides making everything code, a good deal of Graphene’s magic lies in the ergonomics of the development loop. When an agent works with data, it needs to be able to discover what’s available, make changes, validate that those changes are correct, see the results, and repeat as needed. Most tools today require token-inefficient MCPs, awkward build steps, or require the human operator to log in to a SaaS portal and screenshot the result to show the agent how its work turned out. In Graphene, changes percolate instantaneously across all their dependencies, and visual elements are viewable locally using tools that your coding agent already has.
Check out the project on GitHub here.
What’s next
Imagine I’m a marketer and I’m strategizing my next campaign. I ask an agent in Slack, “What demographic characteristics do our top customers have in common that I could target?” The agent then uses Graphene to grok the available data, understand what defines a “top customer,” and look at past campaign data to see what’s been tried. It then presents its findings in Slack along with some recommendations.
I find something interesting: our highest-LTV customers all came from a single conference we sponsored two years ago. I want to dig in further, so I click a link into a web app where I can circle specific data points and ask follow-up questions. After some iteration I have a report I’m confident in and I share it with my team, where they can dive in and start their own agent-assisted investigations.
This is what we believe the future of data analytics looks like. It’s embedded in where you work, and agents do all the querying and visualizing backed by the version-controlled knowledge of your data team context engineering team. By significantly reducing the friction to ask questions, everyone builds a habit of grounding their day-to-day work in data-backed intelligence.
That’s what’s coming next. If you’re interested in piloting it with us, please drop us a line here.